
AI编译器

AI编译器
AI 编译器是一种针对 AI 和机器学习应用特别优化的编译器,它能够满足推理场景和训练场景不同需求,
将高级语言编写的程序或者训练好的模型文件转换成可以在特定硬件上高效执行的程序。
1)以 Python 语言为前端
2)拥有多层 IR 设计
3)面向神经网络深度优化
4)针对不同芯片架构设计
目标
- 性能优化:极致降低训练、推理耗时,提升吞吐量。
- 资源利用:最大化硬件资源利用率(CPU/GPU/NPU),实现最优能效比。
- 模型压缩:压缩模型体积与计算量,适配移动端/嵌入式设备资源限制。
- 硬件兼容性:生成跨平台可执行代码,覆盖异构硬件架构(x86/ARM/NPU)。
- 梯度计算:自动生成高效反向传播代码,支持动态计算图微分。
- 并行计算:实施数据/模型/流水线并行策略,充分利用多设备算力。
计算图
计算图由基本数据结构张量(Tensor)和基本运算单元算子构成。在计算图中通常使用节点来表示算子,节点间的有向边(Directed Edge)来表示张量状态,同时也描述了计算间的依赖关系。如图所示。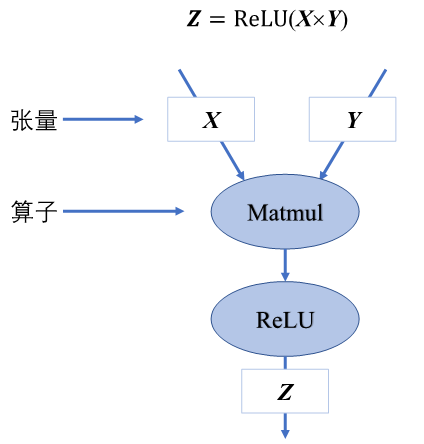
图层优化
将一种计算图结构,在算术结果不改变的情况下,基于一系列预先写好的模板,对计算图进行相应的图
替换操作。
常量折叠
常量折叠:将计算图中可以预先确定输出值的节点替换
成常量,并对计算图进行一些结构简化的操作。AI 编译
器会对计算图中的每个操作节点进行分析,判断其是否
可进行常量折叠。如果可以,则通过计算得到结果替换
该节点
冗余节点消除
死代码消除
冗余节点消除
公共表达式消除:当模型中出现了公共子图,如一个输出是另外两个同类型同参数的节点输入,则可以考虑将这些分支合并成一个分支。
算子融合
算子融合:通过将多个细粒度的计算操作合并为单个复合算子,显著提升了深度学习模型的执行效率。它减少了内核启动次数和中间结果的频繁内存读写,有效降低了计算开销和内存带宽压力。
数据布局转换
cudagraph
原本5个kernel需要cpu通知五次,现在一次性把五个kernel任务交给gpu
tvm
① 从 TensorFlow、PyTorch 或 ONNX 等框架导入模型。
② 翻译成 TVM 的高级模型语言 Relay。图级优化
③ 将Relay表示降级为TE表示。了解“计算什么”
④ 使用 auto-tuning 模块 AutoTVM 或 AutoScheduler 搜索最佳 schedule。寻找“如何计算”
⑤ 为模型编译选择最佳配置。最优计算+调度
⑥ 降级为张量中间表示(TIR,TVM 的底层中间表示)。后端优化
⑦ 编译成机器码。
MLIR
MLIR(Multi-Level Intermediate Representation)是一种高度模块化的编译器基础设施,专门设计用于解决异构计算和领域特定编译的挑战。其核心思想是通过分层中间表示(IR)和可扩展的方言(Dialect)系统,统一不同抽象级别的计算表达,从而连接高级框架(如TensorFlow/PyTorch)与底层硬件(如CPU/GPU/TPU)。
- Title: AI编译器
- Author: Ikko
- Created at : 2026-01-26 20:12:27
- Updated at : 2026-03-06 22:35:58
- Link: http://ikko-debug.github.io/2026/01/26/bianyi/
- License: This work is licensed under CC BY-NC-SA 4.0.