
cuda

前言
CUDA 编程需要理解线程与硬件的物理映射,并优化显存(Global Memory)访问以提升性能。
核心映射
Grid/Block/Thread 在物理资源上的占用情况。
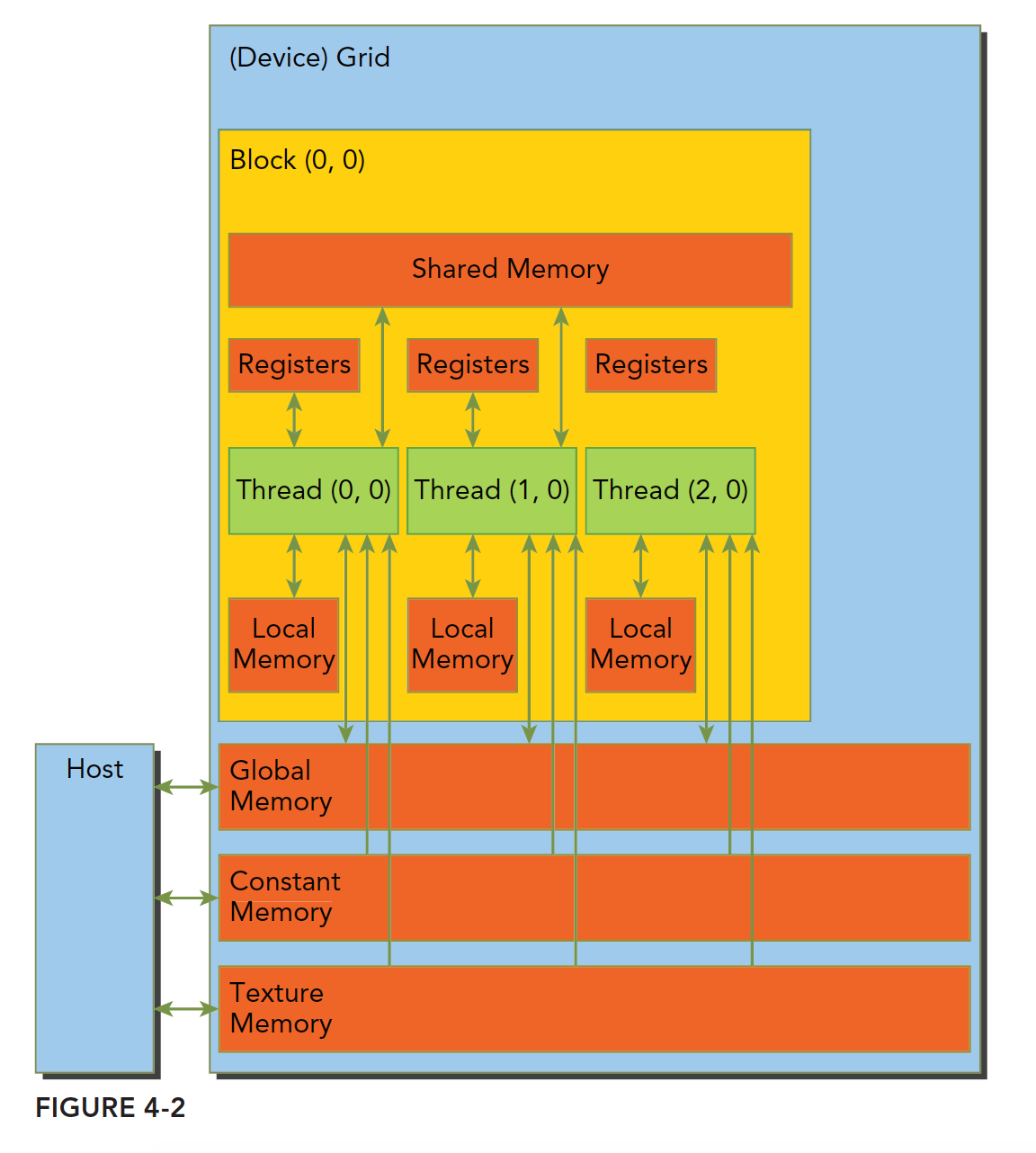
| 软件层级 (Software) | 硬件真身 (Hardware) | 说明 |
|---|---|---|
| Grid | Device (GPU) | 对应显存 (Global Memory)。所有线程可见,但访问延迟较高。 |
| Block | SM (流多处理器) | Block 被分配给 SM 后会驻留直到结束。Block 间无法通信,Block 内可通过 Shared Memory 通信。 |
| Thread | CUDA Core (SP) | 最小执行单位。拥有私有的 Registers (极速访问)。 |
dim3 block(128),则threadIdx.x = 0 ~ 127
dim3 grid(10),则blockIdx.x = 0 ~ 9
blockDim.x,一个 block 在 x 方向的线程数量。dim3 block(256),则 blockDim.x = 256
gridDim.x,一个 grid 在 x 方向的 block 数量。dim3 grid(20),则 gridDim.x = 20
Warp (线程束)
Warp 是 GPU 执行的基本单位。
threadIdx.x 和 threadIdx.y 就是当前线程在它所属的那个 Block 里的坐标。
GPU 执行层级:
Grid
└── Block (线程块)
└── Warp (线程束)
└── Thread (线程)
假设定义 dim3 blockSize(32, 16);:
Block 就像一个电影院,有 32 列(x轴),16 排(y轴)。
- 执行机制:GPU 采用 SIMT (Single Instruction, Multiple Threads) 架构,32 个线程 (Warp) 同时执行相同指令。
- **分支发散 (Warp Divergence)**:如果
if-else分支导致 Warp 内线程执行路径不同,硬件将串行化执行各分支,降低并行效率。
硬件规定: 在一个 Block 中,线程是按照 x 轴优先 的顺序被编入 Warp 的。
Warp 0: threadIdx(0,0) 到 threadIdx(31,0)
Warp 1: threadIdx(0,1) 到 threadIdx(31,1)(假设 x 维度是 32)
控制分支 (Control Divergence)
1. SIMD 执行与分支问题
当 Warp 中的所有线程在处理数据时都遵循相同的执行路径(控制流)时,SIMD 执行效果很好。例如,对于 if-else 结构,当 Warp 中的所有线程执行 if-path 或全部执行 else-path 时,执行效果很好。
然而,当 Warp 中的线程采用不同的控制流路径时,SIMD 硬件将对这些路径进行多次遍历,每个路径一次。例如,对于 if-else 结构,如果 Warp 中的一些线程遵循 if-path 而另一些线程遵循 else-path,硬件将执行两次:
- 一次执行遵循 if-path 的线程
- 另一次执行遵循 else-path 的线程
- 在每次遍历期间,遵循另一路径的线程将不被允许产生效果(非活动状态)
当同一 Warp 中的线程遵循不同的执行路径时,我们说这些线程表现出控制分支,即它们在执行中分岔。
2. 分支执行机制
分支 Warp 执行的多通道方法扩展了 SIMD 硬件实现 CUDA 线程的完整语义的能力。虽然硬件对 Warp 中的所有线程执行相同的指令,但它有选择地只让这些线程在对应于它们所采取的路径的通道中产生效果,从而使每个线程都可以看似采取自己的控制流路径。
代价:
- 硬件需要执行额外的通道,以允许 Warp 中的不同线程做出自己的决策
- 每个通道中由非活动线程消耗的执行资源
架构演进:
- Pascal 及之前: 这些通道是按顺序执行的,一次通道执行完毕后另一次通道执行
- Volta 及之后: 引入独立线程调度,这些通道可以并发执行,一次通道的执行可能与另一次通道的执行交错进行
3. if-else 分支示例
假设线程 0-31 组成的 Warp 到达 if-else 语句:
- 线程 0-23 走 then-path (执行代码块 A)
- 线程 24-31 走 else-path (执行代码块 B)
执行过程:
- 第一次遍历: 线程 0-23 执行 A,线程 24-31 处于非活动状态
- 第二次遍历: 线程 24-31 执行 B,线程 0-23 处于非活动状态
- 重新汇聚: 所有线程一起执行后续代码 C
4. 循环分支示例
分支也可能在其他控制流结构中出现,如 for 循环。假设每个线程执行不同数量的循环迭代(4-8 次):
- 前 4 次迭代: 所有线程都活动并执行循环体
- 剩余迭代: 一些线程执行循环体,其他线程因已完成迭代而不活动
5. 识别控制分支
通过检查控制结构的决策条件来确定是否会导致线程分支:
会导致分支:
1 | if (threadIdx.x > 2) { |
循环分支:
1 | for (int i = 0; i < threadIdx.x; i++) { |
6. 边界条件处理
处理线程映射到数据时,使用控制分支的一个普遍原因是处理边界条件。这是因为线程总数需要是线程块大小的倍数,而数据大小可以是任意数字。
示例: 向量加法 Kernel
1 | __global__ void addVecKernel(float *A, float *B, float *C, int n) { |
我们在 addVecKernel 中有一个 if(i < n) 语句。这是因为不是所有的矢量长度都可以表示为块大小的倍数。例如,假设矢量长度为 1003,我们选择 64 作为块大小。需要启动 16 个线程块来处理所有 1003 个矢量元素。然而,这 16 个线程块将有 1024 个线程。我们需要禁用线程块 15 中的最后 21 个线程,以防止它们执行原始程序不期望或不允许的工作。请记住,这 16 个块被分成 32 个 warps。只有最后一个 warp(即最后一个块中的第二个 warp)会有控制分支。
7. 性能影响分析
控制分支的性能影响会随着数据规模的增加而减小:
| 向量长度 | 总 Warps | 分支 Warps | 影响比例 | 性能影响 |
|---|---|---|---|---|
| 100 | 4 | 1 | 25% | 显著 |
| 1,000 | 32 | 1 | ~3% | 约 3% |
| 10,000 | 313 | 1 | <1% | 可忽略 |
结论: 对于大规模数据处理,边界条件导致的控制分支影响通常可以忽略。即使分支将 Warp 执行时间加倍,对总执行时间的净影响也很小。也因此,blockdim通常为32的倍数,保证一个 Warp 刚好是一行(或一行的一部分),这使得内存访问非常整齐(合并访存),且分支逻辑最简单。
资源约束与占用率
1. 动态资源分配
前面的讨论没有考虑其他资源约束的影响,例如寄存器和共享内存。在 CUDA 内核中声明的自动变量存储在寄存器中。一些内核可能使用许多自动变量,而其他内核可能使用较少的自动变量。
因此,应该预期:
- 一些内核每个线程需要许多寄存器
- 其他内核每个线程需要较少的寄存器
通过在 SM 中动态划分寄存器,SM 可以:
- 容纳许多块,如果它们每个线程需要较少的寄存器
- 容纳较少的块,如果它们每个线程需要更多的寄存器
2. 寄存器限制与占用率
需要注意寄存器资源限制对占用率的潜在影响。例如:
- Ampere A100 GPU: 允许每个 SM 最多使用 65536 个寄存器
- 满占用率所需: 每个 SM 需要支持 2048 个线程,这意味着每个线程不应使用超过
个寄存器
关键问题: 如果一个内核每个线程使用 64 个寄存器,会发生什么?
可以使用 65536 个寄存器支持的最大线程数为:
在这种情况下,无论块大小设置为多少,内核都无法以满占用率运行。相反,占用率最多为 50%。
3. 寄存器溢出与性能权衡
在某些情况下,编译器可能执行寄存器溢出 (Register Spilling),以减少每个线程的寄存器需求,从而提高占用率水平。
代价:
- 线程需要访问内存中的溢出寄存器值
- 执行时间增加
- 可能导致网格的总执行时间增加
对共享内存资源的约束也会进行类似的分析。
4. 性能悬崖案例
假设场景:
- 实现一个内核,每个线程使用 31 个寄存器
- 配置为每个块 512 个线程
初始情况:
- SM 将同时运行:
个块 - 线程使用寄存器:
个,低于 65536 的限制 - 占用率: 100%
添加两个自动变量后:
- 每个线程使用寄存器增加到 33 个
- 2048 个线程所需寄存器:
个 - 超过了 65536 的寄存器限制!
运行时处理:
- CUDA 运行时系统将每个 SM 仅分配给 3 个块(而不是 4 个)
- 所需寄存器数降低到:
个 - 在 SM 上运行的线程数:
个 - 占用率下降到 75%
性能悬崖 (Performance Cliff):
仅通过使用两个额外的自动变量,程序看到了占用率从 100% 降至 75% 的减少。这就是性能悬崖的典型表现:资源使用的轻微增加可能导致并行性和性能显著减少。
5. 复杂的资源相互作用
所有动态划分的资源的约束以复杂的方式相互作用。准确确定每个 SM 中运行的线程数可能是困难的。
解决方案:
- 参考 CUDA 占用率计算器 (可在线下载),这是一个可下载的电子表格
- 根据内核对资源的使用,计算给定设备实现上每个 SM 上实际运行的线程数
CPU vs GPU 寄存器设计对比
1. 基本特性对比
| 特性 | CPU 寄存器 | GPU 寄存器 |
|---|---|---|
| 分配方式 | 固定 (Static) | 动态 (Dynamic) |
| 分配策略 | 每个线程无论用不用,都分到固定数量的寄存器(例如 x86-64 的 16 个通用寄存器) | 根据 Kernel 的复杂度分配。简单的 Kernel 分少点,复杂的给多点 |
| 对并行的影响 | 寄存器数量不影响同时运行的线程数 | 直接相关。每个线程要的越多,SM 能塞下的线程就越少(占用率降低) |
| 硬件实现 | 物理上离核心极近,总数极小 | 物理上是一个巨大的寄存器堆(Register File) |
2. 为什么 CPU 寄存器不能做大?
这是一个深刻的设计权衡问题。CPU 寄存器设计得小,不是因为”造不大”,而是为了追求极致的单核响应速度和指令执行效率。
如果把 CPU 寄存器做成像 GPU 那么大,CPU 就无法维持现在的超高主频(4GHz+)了。
核心原因有三:
原因 1: 物理定律的限制——距离与速度
在芯片设计中,容量、速度和物理距离构成一个”不可能三角”。
访问延迟限制:
- 寄存器文件的访问必须在一个时钟周期内完成
- CPU 的主频非常高(通常是 GPU 的 2-3 倍),这意味着电流在电路中跑的时间极其有限
搜索开销:
- 寄存器堆本质上是一个存储阵列
- 如果有 65,536 个寄存器(像 GPU 那样),为了定位并取出某个寄存器的数据,逻辑门电路的层数会增加
- 电信号传输的路径会变长
后果:
- 如果寄存器太大,访问它就可能需要 2 个甚至更多周期
- 这对于依赖”单线程串行速度”的 CPU 来说是毁灭性的
原因 2: 指令集编码的限制(位宽限制)
CPU 的每一条机器指令都需要告诉硬件:我要操作哪几个寄存器。
指令空间限制:
- 在 x86 或 ARM 这种 32/64 位指令集中,指令的长度是固定的
- 如果有 16 个寄存器,只需要 4 位 (
) 就能表示 - 如果有 65,536 个寄存器,则需要 16 位 才能表示
后果:
- 仅仅为了指明操作哪个寄存器,指令中就要浪费大量的位数
- 这会导致指令变得臃肿,占用更多的指令缓存 (I-Cache)
- 降低取指效率
原因 3: 设计哲学的差异——低延迟 vs 高吞吐
这是最根本的原因。
CPU 追求的是”低延迟”:
- 优化目标是尽快完成单个任务(如响应用户输入、执行顺序逻辑)
- 配备庞大的缓存体系(L1/L2/L3),使数据尽可能接近核心
- 通过减少访问延迟而不是线程切换来提高性能
GPU 追求的是”高吞吐”:
- 优化目标是最大化单位时间内的总处理能力
- 内存访问延迟较高,故采用大寄存器堆设计
- 通过同时存储数千个线程的上下文数据,实现细粒度的任务切换,使计算单元持续工作
3. 主频与寄存器大小的关系
主频的含义:
主频(Clock Speed)直接决定了 CPU 单位时间内执行指令的数量。CPU 的所有操作都以时钟周期为基本单位:
- 1.0 GHz: 每秒执行 10 亿个时钟周期
- 5.0 GHz: 每秒执行 50 亿个时钟周期
这意味着主频越高,一个时钟周期(Clock Cycle)的时间就越短:
- 在 5GHz 下,一个周期只有 0.2ns(纳秒)
- 电信号在这段时间内只能在芯片的硅片上移动几厘米
寄存器大小的限制:
这也是为什么 CPU 寄存器不能做大的根本原因:
如果 CPU 的主频是 5GHz,它要求数据必须在 0.2ns 内:
- 从寄存器取出
- 送入运算单元
- 再存回寄存器
如果寄存器堆太大:
- 信号寻找地址、穿过复杂的逻辑门电路、最后抵达目的地的时间就会超过 0.2ns
- 整个时钟周期就会崩溃,CPU 无法稳定运行
结论: 为了维持超高主频,CPU 必须保持极小、极快的寄存器架构。
4. 为什么不能无限提升主频?
你可能发现,CPU 主频在过去十几年里一直卡在 5GHz∼6GHz 左右,没能像核心数那样翻倍增长。这是因为两个死对头:功耗与发热。
动态功耗公式:
其中
提升主频的代价:
- 当提升主频时,为了保持信号稳定,通常还需要提升电压
- 这就导致功耗呈立方级增长
结果:
- 频率再往上提一点,芯片就会变成一个热得发红的”小电炉”
- 甚至可能烧毁
5. CPU vs GPU 的主频与寄存器策略对比
| 维度 | CPU | GPU |
|---|---|---|
| 主频 | 5GHz+ | 1.5GHz∼2.5GHz |
| 寄存器大小 | 极小(16 个) | 巨大(65536+ 个) |
| 寄存器分配 | 静态固定 | 动态分配 |
| 设计哲学 | 极速响应,单核性能 | 极致吞吐,并行处理 |
| 掩盖延迟方式 | 庞大的 L1/L2/L3 缓存 | 大寄存器堆 + 任务切换 |
为什么选择这样的策略:
CPU: 宁愿忍受高功耗和发热,也要把主频推到 5GHz 以上,并配以极小的寄存器,以此换取极强的单核性能
GPU: 主频通常只有 1.5GHz∼2.5GHz。因为它不靠跑得快,而是靠”人多”。由于频率低,它允许寄存器堆设计得很大,从而实现零开销的任务切换
内存层级与变量声明
通过不同的声明方式,在物理硬件上划分了资源的使用。在 GPU 中,一个 int a 变成什么完全取决于你把它写在了哪里,以及加了什么前缀。
1. 内存语法、作用域与生命周期
| 修饰符 | 变量名称 | 存储器 | 作用域 | 生命周期 |
|---|---|---|---|---|
float var |
寄存器 | 线程 | 线程 | |
float var[100] |
本地 | 线程 | 线程 | |
__shared__ |
float var* |
共享 | 块 | 块 |
__device__ |
float var* |
全局 | 全局 | 应用程序 |
__constant__ |
float var* |
常量 | 全局 | 应用程序 |
Register (SRAM-like)
↓
L1/L2/L3 Cache ← SRAM
↓
Main Memory ← DRAM
↓
SSD/HDD
1.1 CPU 与 GPU 内存层级对应
| 内存类型 | CPU 对应 | GPU 对应 |
|---|---|---|
| Register (SRAM) | GPR / SIMD regs | 每线程大量寄存器文件 (massive per-thread register file) |
| L1 SRAM | L1 I/D cache | per-SM L1 cache |
| L2/L3 SRAM | Cache hierarchy | Shared L2 cache |
| Software-managed SRAM | 几乎没有 | Shared Memory |
| DRAM | main memory (DDR) | Global Memory (GDDR/HBM) |
HBM 用超宽总线获得极高总带宽;DDR 用高频率提升单线速率,但总带宽较低。
CPU:
• latency sensitive
• capacity sensitive
GPU:
• bandwidth bound
• massive parallel read
设备存储器的重要特征:
| 存储器 | 片上/片外 | 缓存 | 存取 | 范围 | 生命周期 |
|---|---|---|---|---|---|
| 寄存器 | 片上 | n/a | R/W | 一个线程 | 线程 |
| 本地 | 片外 | 1.0以上有 | R/W | 一个线程 | 线程 |
| 共享 | 片上 | n/a | R/W | 块内所有线程 | 块 |
| 全局 | 片外 | 1.0以上有 | R/W | 所有线程+主机 | 主机配置 |
| 常量 | 片外 | Yes | R | 所有线程+主机 | 主机配置 |
| 纹理 | 片外 | Yes | R | 所有线程+主机 | 主机配置 |
2. 线程私有变量的物理实现
当在核函数内声明 float x = 0.5f; 时,物理实质为:
- 重复分配: 如果启动了 100 万个线程,GPU 的寄存器堆里会瞬间为每个线程划出空间
- 逻辑隔离: 线程 A 对
x的修改对线程 B 完全不可见,实现了强隔离性 - 可扩展性: 这种设计允许用简洁的代码处理海量数据
3. 本地内存的特性与陷阱
本地内存的产生原因
虽然名称为”本地”,但其物理位置在**显存(DRAM)**中。以下三种情况会触发本地内存的使用:
- 寄存器溢出: 变量过多导致寄存器文件饱和
- 动态索引数组: 如
arr[i],编译器无法编译期确定位置 - 大型变量: 声明的结构体或数组超过寄存器容量
本地内存与全局内存的对比
| 特性 | 全局内存 (Global Memory) | 本地内存 (Local Memory) |
|---|---|---|
| 物理位置 | 显存 (DRAM) | 显存 (DRAM) |
| 作用域 | 网格级:所有线程访问 | 线程级:仅当前线程访问 |
| 生命周期 | 程序运行期间 | 随线程生存周期 |
| 访问延迟 | 数百个周期 | 数百个周期(L1缓存优化) |
| 典型用途 | 主输入输出数据 | 寄存器装不下的局部变量 |
本地内存的性能特性
尽管在 DRAM 上,本地内存的访问经过了硬件优化:
- 自动合并: 硬件重排地址确保 Warp 内 32 个线程的本地变量访问在物理显存上连续
- 缓存辅助: 现代 GPU 将本地内存数据缓存在 L1 缓存中,访问速度可接近寄存器
- 监控方法: 使用编译选项
--ptxas-options=-v查看lmem值( lmem = 寄存器放不下,被“挤”到显存里的线程私有变量),判断寄存器溢出程度
补充:L1TEX 与 lmem 的关系
- L1TEX 是硬件单元,不是编译指标: 它可理解为 L1 Cache + Texture/Load-Store 访问通路,是访存“第一站”
- 访问范围: global memory、local memory(lmem)、texture memory、surface memory 的访问都会经过 L1TEX
- 和 lmem 的关联: lmem 本质是落在显存里的线程私有数据(常由寄存器溢出触发);lmem 增多通常会带来更多 L1TEX 请求与带宽压力
- Profiling 关注项: 可重点查看
l1tex__t_requests、l1tex__t_sectors、l1tex__throughput等指标 - 实战判断链路: 若
ptxas显示lmem > 0,且 Nsight Compute 中 L1TEX 利用率高或 miss 偏高,通常意味着“寄存器溢出 → lmem 增加 → L1TEX 压力上升 → 性能下降”
4. 共享内存的协作机制
共享内存是唯一允许同一线程块内不同线程交互的快速存储(除去极慢的全局内存):
- 数据交换: 线程 0 从全局内存搬数据到共享内存,调用
__syncthreads()后,线程 1 可读取该数据 - 数据重用: 通过共享内存减少冗余的全局内存访问
- 同步要求:
__syncthreads()确保块内所有线程在逻辑上达成同步
5. 常量内存与广播访问
常量内存(__constant__)适合存放只读、小尺寸、会被大量线程重复使用的数据;共享内存(__shared__)则适合线程块内部的数据协作。二者最关键的区别在于访问模式优化方向完全不同。
| 特性 | 常量内存 (Constant Memory) | 共享内存 (Shared Memory) |
|---|---|---|
| 作用 | 存放只读数据(kernel 中不会修改) | 用于线程块内部的数据共享 |
| 访问权限 | GPU 线程只读,CPU 可写 | GPU 线程可读可写 |
| 作用范围 | 所有线程、所有 block 可访问 | 仅同一个 block 内线程可访问 |
| 生命周期 | kernel 执行期间一直存在 | block 执行期间存在 |
| 大小限制 | 通常 64KB | 每个 SM 一般 48KB-100KB+(架构相关) |
| 访问速度 | 有常量缓存(constant cache),广播访问非常快 | 接近寄存器速度(若无 bank conflict) |
| 访问模式 | 同一 warp 访问同一地址效率最高(广播) | 任意访问,但需避免 bank conflict |
| 典型用途 | 参数表、查找表、固定系数 | block 内中间计算数据、tile 数据 |
常量内存只有在 broadcast 时才快。如果 warp 内访问不同地址,就会明显变慢。这是因为常量内存的硬件设计目标是“广播优化”,而不是“并行多地址访问优化”。核心原因在于 constant cache 的访问机制。
下面从 warp 执行模型、constant cache 结构、实际执行流程三个角度说明。
5.1 Warp 是常量内存访问的基本观察单位
GPU 线程不是完全独立执行的,而是 32 个线程组成一个 warp,同步执行同一条指令。例如:
1 | x = coeff[i]; |
warp 内 32 个线程会同时执行这条 load 指令。关键问题是:这 32 个线程访问的是不是同一个地址。
5.2 Constant cache 的设计是广播
如果 warp 中所有线程都访问同一个地址:
1 | thread0 -> coeff[5] |
GPU 只需要读取一次 coeff[5],然后把结果广播给整个 warp。因此这种访问模式非常快。
5.3 Warp 内地址分散时会退化为多次 transaction
如果访问模式变成:
1 | thread0 -> coeff[0] |
constant cache 无法一次广播,硬件会把这一次 warp load 拆成多个 transaction。warp 内有多少个不同地址,就需要多少次 transaction,因此延迟会显著上升。
CUDA Programming Guide 对此的表述是:一个 warp 对常量内存的访问,会按照其中不同地址的数量被服务为对应数量的 transaction。
| warp 访问模式 | transaction 数 |
|---|---|
| 32 线程读同一地址 | 1 |
| 32 线程读 2 个地址 | 2 |
| 32 线程读 32 个地址 | 32 |
5.4 为什么 global memory 不会表现成这样
global memory 主要依赖 memory coalescing。例如:
1 | thread0 -> A[0] |
如果地址连续,GPU 会把多个线程的请求合并成少量大事务。因此 global memory 更适合连续访问;constant memory 则更适合同地址广播访问。
可以把 CUDA 中几种典型存储的设计哲学概括为:
1 | constant memory = broadcast optimized |
5.5 一个直接的优化判断
如果你看到这样的代码:
1 | value = table[threadIdx.x]; |
而 table 放在 constant memory 中,这通常是很差的访问模式,因为一个 warp 内线程大概率在访问不同地址。此时更适合考虑使用 shared memory 或 global memory。
6. 全局内存的持久性
使用 __device__ 或 __constant__ 在核函数外部声明的变量在多次核函数调用间保持不变,行为类似于 CPU 程序中的全局变量:
- 生命周期: 从程序启动到终止
- 初始化: 由 CPU 端通过 CUDA Runtime API 控制
- 释放: 显式调用
cudaFree()或程序终止时释放
7. 程序员的资源预算原则
CUDA 编程不仅涉及逻辑设计,更涉及资源预算:
- 频繁使用的标量: 放入寄存器(默认写法)
- 块内需交换的数据: 声明为
__shared__ - 巨大的输入输出: 放在
__device__(通过指针传入) - 监控溢出: 减少局部变量数量以避免寄存器溢出
从 1D 到 Memory Coalescing
1. 1D 索引计算
公式 i = blockIdx.x * blockDim.x + threadIdx.x 用于将并行线程映射到线性内存地址。
- Thread ID:作为指针算术 (Pointer Arithmetic) 的偏移量。
- Thread 0 ->
BaseAddr + 0 - Thread 1 ->
BaseAddr + 4 bytes
2. 内存合并 (Memory Coalescing)
当一个 Warp 发起内存请求时,硬件会尝试合并访问:
- **合并访问 (Coalesced)**:线程访问连续地址 (
k, k+1, k+2...)。硬件可将 32 个请求合并为一个 128-byte 的事务。 - **非连续访问 (Strided/Random)**:地址跳跃或乱序。硬件需发射多个独立事务,导致带宽浪费。
结论:应确保相邻
threadIdx访问相邻内存地址。
Grid-Stride Loop
Grid-Stride Loop 模式用于处理数据量超过线程总数的情况,并提高代码复用性。
1 | __global__ void vectorAdd(const float *A, const float *B, float *C, int N) { |
- 解耦:Kernel 执行不受 Grid 大小限制。
- 效率:减少线程创建与销毁的开销。
2D 矩阵与 Flattening
1. 坐标映射 (Mapping)
利用 CUDA 的 2D 索引计算坐标:
- **Col (列 / x)**:
blockIdx.x * blockDim.x + threadIdx.x - **Row (行 / y)**:
blockIdx.y * blockDim.y + threadIdx.y
2. 地址压扁 (Flattening)
C 语言矩阵通常采用行主序 (Row-Major) 存储。
3. Naive GEMM 实现
以下是基础的矩阵乘法实现。
1 | __global__ void matrixMulNaive(const float *A, const float *B, float *C, int N) { |
4. 性能分析
- **内存受限 (Memory Bound)**:计算一个元素需要多次访问 Global Memory。
- 延迟:Global Memory 访问延迟较高,导致计算单元等待数据。
Roofline 模型
Roofline 模型用于分析应用程序在特定硬件上的性能瓶颈。
1. 核心指标
- 算力峰值 (
):硬件每秒能完成的最大浮点运算次数 (FLOPS)。 - 带宽峰值 (
):硬件每秒能完成的最大内存交换量 (Bytes/s)。 - 计算强度 (
):也称为算术强度 (Arithmetic Intensity),指每字节内存交换所完成的浮点运算次数。
2. 性能模型
应用程序的可达性能
3. 瓶颈分析
- 带宽受限 (Memory Bound):当
时, 。此时性能受限于内存带宽,优化方向为减少内存访问或提高内存访问效率(如 Coalescing)。 - 计算受限 (Compute Bound):当
时, 。此时性能受限于硬件算力,优化方向为提高计算并行度或使用更高效的指令。
tiled GEMM 实现
以下是使用 Shared Memory 优化的矩阵乘法实现。
1 | __global__ void matrixMulShared(const float *A, const float *B, float *C, int N) { |
代码详细解读
1. 索引变量的物理含义
bx,by(Block Index):bx = blockIdx.x: 当前 Block 在 Grid 中的列方向索引。by = blockIdx.y: 当前 Block 在 Grid 中的行方向索引。- 这就好比我们将大矩阵 C 切分成许多小方块(Tile),
bx和by就是这些小方块的坐标。
tx,ty(Thread Index):tx = threadIdx.x: 当前线程在 Block(Tile)内部的列坐标。ty = threadIdx.y: 当前线程在 Block(Tile)内部的行坐标。- 每个 Block 内部有
TILE_WIDTH * TILE_WIDTH个线程,每个线程负责计算 Tile 中的一个点。
2. 全局坐标映射 (Global Coordinate Mapping)
代码中的 row 和 col 计算是为了找到当前线程负责计算的 C 矩阵中的具体元素位置。
int row = by * TILE_WIDTH + ty;by * TILE_WIDTH: 确定当前 Block 的起始行(全局行偏移)。+ ty: 加上线程在 Block 内部的行偏移。- 结果:
row是该线程对应的 C 矩阵元素的全局行号。
int col = bx * TILE_WIDTH + tx;bx * TILE_WIDTH: 确定当前 Block 的起始列(全局列偏移)。+ tx: 加上线程在 Block 内部的列偏移。- 结果:
col是该线程对应的 C 矩阵元素的全局列号。
3. 对应原因
矩阵乘法 row 行和 col 列进行点积。
- 确定 C 的位置: 通过
row和col,每个线程唯一锁定了一个中的元素。 - 加载数据:
- 加载
时,我们需要 的第 row行。 - 加载
时,我们需要 的第 col列。
- 加载
Row-Major Layout (行主序布局)
cuda中,不写二维数组,A[row * N + (p * TILE_WIDTH + tx)]
矩阵在显存中存储是按行优先的顺序排列的,即行主序 (Row-Major Order)。所有行实际上是连续存储的。
Tiling 性能分析:全局内存流量减少的数学推导
问题背景
对于矩阵乘法
不使用 Tiling 的全局内存访问量
计算模式:
- 计算
中的每一个元素 需要读取 的第 行( 个元素)和 的第 列( 个元素) 矩阵共有 个元素
总访问次数:
其中每个元素计算需要读取
使用 Tiling 的全局内存访问量
分块策略:
- 设块大小(Tile Width)为
(例如 ) - 将
的计算任务划分为 个 的子块 - 每个线程块包含
个线程,负责计算 中一个 的区域
分阶段计算:
整个计算过程被分为
数据搬运:块内
个线程协作从全局内存搬运: 的一个 子块( 个元素) 的一个 子块( 个元素) - 总计:
个元素被搬运到共享内存
数据重用:共享内存中的每个元素被重复使用
次 中的每个元素被同一行的 个线程使用 中的每个元素被同一列的 个线程使用
单个块的全局内存读取:
计算一个
全网格的总访问量:
全网格共有
性能提升比例
流量减少倍数:
结论:使用块大小为
实例分析:
- 若
,全局内存流量减少到原来的 - 若
,全局内存流量减少到原来的
关键洞察
Tiling 性能提升的本质在于数据重用:
- 不使用 Tiling:每个数据从全局内存读取后仅使用一次
- 使用 Tiling:每个数据从全局内存读取后,在共享内存中被
个线程重复使用 次,实现了 倍的重用
这种局部性优化是 GPU 编程中提升内存受限应用性能的核心技术。
突破串行限制:双缓冲与流水线优化
瓶颈分析:串行执行的代价
在基础的 Shared Memory Tiling 实现中,Kernel 的执行流程是典型的同步-阻塞循环:
- Load: 从 Global Memory 加载数据到 Shared Memory。
- Sync:
__syncthreads()等待数据就绪。 - Compute: 基于 Shared Memory 进行矩阵乘计算。
- Sync:
__syncthreads()等待计算完成,准备下一轮加载。
从系统架构的视角,这种执行模式导致了严重的**硬件资源闲置 (Underutilization)**:
- 当 Memory Unit (LD/ST) 忙于搬运数据时,计算核心 (ALU/Tensor Core) 处于空闲状态,等待 IO 结束。
- 当计算核心满载运转时,内存带宽却处于闲置状态。
用一个形象的比喻:厨师(ALU)必须等仓库管理员(Memory Unit)搬完所有食材(Load),才能开始切菜(Compute)。在搬运的数百个时钟周期里,案板是空的,厨师停工无事可做。
这种串行模式限制了 GPU 的 计算与访存重叠 (Overlap) 能力,无法充分掩盖长达数百个时钟周期的访存延迟。
核心原理:软件流水线化 (Software Pipelining)
为了打破这一瓶颈,我们引入双缓冲 (Double Buffering) 技术。其核心思想是构建一个软件流水线,利用 GPU 的 指令级并行 (Instruction Level Parallelism, ILP) 能力,实现”搬运”和”计算”的真正并发。
Ping-Pong 缓冲区设计
我们分配两份物理 Shared Memory 空间(Buffer 0 和 Buffer 1),分别称为 Ping-Pong Buffer:
- Buffer 0 (Ping): 当前时刻用于计算的活跃缓冲区。所有线程都在消费其数据。
- Buffer 1 (Pong): 当前时刻用于异步预取的阴影缓冲区,为下一轮循环提前准备数据。
硬件视角的时序增益
通过指令重排,我们可以使总执行时间趋近于计算和访存中较大的一方,而非两者的简单相加:
$$\text{Total Time} \approx \sum_{k} \max(\text{Time}{\text{compute}, k}, \text{Time}{\text{memory}, k+1})$$
而在串行模式下,总时间为:
$$\text{Total Time}{\text{serial}} = \sum{k} (\text{Time}{\text{load}, k} + \text{Time}{\text{compute}, k})$$
流水线重叠效果示意图:
1 | Time: ---------------------------------------------------------> |
在这个理想情况下,Memory Unit 在搬运下一批数据,而 ALU 正在计算前一批数据。两个独立的硬件单元形成了流水线的两个阶段。
代码实现:基于寄存器预取的软件流水线
在 NVIDIA Ampere 架构(A100)之前,通用的实现方案是利用**寄存器预取 (Register Prefetching)**。这种方式巧妙地将寄存器作为”中转站”,在执行当前阶段计算的同时,异步启动下一阶段的访存请求。
内存布局:双倍 Shared Memory
首先需要将 Shared Memory 的容量翻倍,并通常加上 +1 的 Padding 以避免银行冲突 (Bank Conflicts):
1 | // [2] 代表 Ping-Pong 两个缓冲区阶段 |
Kernel 核心逻辑
1 | __global__ void sgemm_double_buffered(float *A, float *B, float *C, |
机制深究:Consumer-Producer 动态平衡
这种设计通过物理空间的冗余(多一倍的 Shared Memory),巧妙地解决了 Read-After-Write (RAW) 的数据依赖冲突。
我们可以将其理解为一种细粒度的 生产者-消费者模型:
**消费阶段 (Consumer)**:
read_stage的缓冲区始终处于”Full & Valid”状态。所有线程都在读取并消费其中的数据,执行计算。**生产阶段 (Producer)**:
write_stage的缓冲区处于”Deprecated/Empty”状态,等待接收新数据。Store 单元(来自寄存器)源源不断地填充它。**交换瞬间 (Swap)**:通过位运算
idx ^= 1,原先”消费殆尽”的缓冲区瞬间变身为”接收区”,而刚被填满的缓冲区升格为下一轮的”计算区”。
在这个动态平衡中,Memory Unit 和 ALU 两条流水线始终保持了相对独立的执行节奏,只在 __syncthreads() 处进行强制同步,其他时间互不干扰。
现代演进
双缓冲技术以一倍 Shared Memory 空间的代价(Space),换取了计算与访存的时间重叠(Time)。这是解决 Memory Bound 问题的经典且高效的硬件优化手段。
在 NVIDIA Ampere (A100) 及之后的架构中,CUDA 引入了 cp.async (Asynchronous Copy) 指令。相比寄存器预取,其优势包括:
- 绕过寄存器:数据直接从全局内存旁路推送到共享内存,避免了寄存器中转。
- 降低压强:显著减少了寄存器堆 (Register File) 的占用和访问竞争。
- 硬件栅栏:配合
cuda::memcpy_async和__syncwarp()等同步屏障,流水线效率更优。
然而,深刻理解”寄存器预取”这一手工流水线逻辑,依然是每一位 AI Infra 工程师掌握高性能编程的基石。它不仅传授了优化思想,更锻炼了对 GPU 硬件执行流程的深层直觉。
参考文献:
硬件视角的时序图
通过指令重排,我们可以达成以下效果:
$$
\text{Total Time} \approx \sum \max(\text{Time}{\text{compute}}, \text{Time}{\text{memory}})
$$
而不是简单的两者相加。
1 | Time: --------------------------------------------------> |
1D Blocktiling
向量化访存 (Vectorized Memory Access)
向量化访存是通过单条指令加载或存储多个连续数据(如 128 位数据)的技术,旨在进一步压榨带宽并减少指令发射开销。
1. 核心原理
在 CUDA 中,使用向量数据类型(如 float4, int4)可以触发底层硬件的向量加载指令(如 LD.E.128)。
- 单条指令效率:一条 float4 加载指令代替四条标量 float 指令。这减少了指令解码器的压力。
- 对齐要求:向量化类型要求地址必须是其大小的整数倍。例如,float4 要求起始地址必须能被 16 字节整除。若地址未对齐,将导致非法内存访问或性能严重回退。
- 硬件上限:当前 GPU 架构单线程单次访存的最大宽度通常为 128 位 (16 字节)。
2. 为何 float3 性能较差?
float3 占用 12 字节,这并非 2 的幂次。
- 指令拆分:由于没有原生 96 位指令,编译器通常将其拆分为一次 64 位(float2)和一次 32 位(float)加载。
- 对齐失准:在一个 Warp 中,线程 i 访问 data[i] 时,每个线程的起始地址相对于 Warp 边界会产生偏移,导致无法合并为一个连续的 128 字节事务,进而引发严重的访存发散。
内存布局优化:AoS 与 SoA
数据在内存中的排布方式直接决定了合并访问(Coalescing)的成败。
1. AoS (Array of Structures)
结构:struct { float r, g, b; } pixels[N];
内存排列:r g b | r g b | r g b …
GPU 劣势:当线程 i 读取 pixels[i].r 时,相邻线程读取的地址间隔了 g 和 b。这种不连续访问会导致合并访问失败,极大浪费带宽。
2. SoA (Structure of Arrays)
结构:struct { float r[N], g[N], b[N]; } pixels;
内存排列:r r r … | g g g … | b b b …
GPU 优势:相邻线程读取 pixels.r[i] 时,物理地址是完全连续的。这能触发完美的内存合并,是 GPU 编程的首选布局。
并行规约 (Parallel Reduction)
并行规约(如求和、最大值)是并行算法中分治法(Divide and Conquer)的典型应用。
1. 分治累加逻辑
传统的串行累加复杂度为 O(n),而并行规约通过树状结构将复杂度降低至 O(logn)。
- 迭代折半:每一轮迭代,参与计算的线程数减半。活跃线程将数组后半部分的值加到前半部分对应位置。
- 同步要求:在共享内存中进行规约时,每轮迭代后必须调用
__syncthreads(),以确保所有线程都完成了当前层级的计算。
2. 线程束洗牌 (Warp Shuffle) 优化
当规约步长降至 32(即进入同一个 Warp)时,可以使用硬件级别的线程束洗牌函数 __shfl_down_sync()。
- 寄存器交换:数据直接在 Warp 内的寄存器间传递,无需经过共享内存。
- 零同步开销:Warp 内指令天然同步执行,无需
__syncthreads()。 - 边界处理:
__shfl_down_sync若超出 Warp 边界(Lane ID > 31),会自动返回原值,逻辑鲁棒性强。
3. 实现策略对比
Smem Atomic Reduce:每个 Block 计算局部和,最后通过 atomicAdd 汇总到全局地址。
- 优点:实现简单,单个 Kernel 解决。
- 缺点:当 Block 极多时,全局原子操作会导致硬件排队冲突。
Two-Pass Reduce:第一遍计算各 Block 的局部和并存入中间数组,第二遍再启动 Kernel 对中间数组进行规约。
- 优点:无原子冲突,逻辑确定。
- 缺点:需要额外的 Kernel 发射和访存开销。适用于数据量极大、原子冲突显著的场景。
共享内存 Bank Conflict
共享内存被划分为 32 个存储体(Banks),旨在实现并行访问。
1. 冲突原理
映射规则:数据按 4 字节轮询映射到 32 个 Bank。Bank_ID = (Address / 4) % 32。
当多个线程读写同一个 Bank 中的数据时,会由硬件把内存读写请求拆分成 conflict-free requests,进行顺序读写。特别地,当一个 Warp 中的所有线程读写同一个地址时,会触发 broadcast 机制,此时不会退化成顺序读写。
注:触发 broadcast 机制的条件是多个线程读写同一地址(不需要 All)。
在访问 Shared Memory 时,因多个线程读写同一个 Bank 中的不同数据地址,导致 Shared Memory 并发读写退化成顺序读写的现象叫做 Bank Conflict。
2. 2D 数组中的典型冲突
在处理宽为 32 的倍数的 2D 数组时,按列访问(Column-wise Access)是性能杀手:
现象:tile[row][col] 访问时,如果宽度为 32,则 tile[i][0] 和 tile[i+1][0] 的地址间隔正好是 32 个 float,意味着它们会映射到同一个 Bank。
后果:整个 Warp 的 32 个线程会全部撞在同一个 Bank 上,造成 32 路冲突。
3. Padding 优化
通过在声明时增加一列(如 [32][33]),可以强制改变数据的物理映射。
原理:每行末尾多出一个占位符,使下一行的起始位置在 Bank 中产生位移。
效果:原本垂直对齐的”列”在物理 Bank 中变成了斜向分布,从而消除了冲突。
线程束洗牌(warp shuffle)
是指:在同一 warp 内,一个线程可以直接读取另一个线程寄存器中的值。常见接口(以 CUDA 为例)有(省略了模板参数):
1 | __shfl_sync(mask, var, src_lane, width = warpSize) |
核心特性:
- 只在同一个硬件 warp 内生效,width 只能把这个 warp 再划分成若干子组,不能跨多个 warp 做数据交换
- 数据在寄存器间流动,延迟小、带宽高
- 不需要显式 __syncthreads(),但需要正确的 mask 确保活跃线程集合一致
常见洗牌模式
直接索引(__shfl_sync)
- 语义:每个线程从 src_lane 对应线程那里读一个值。
- 典型用途:
- 广播(broadcast):例如 src_lane = 0,将 lane 0 的值广播到整个 warp
上移/下移(__shfl_up_sync / __shfl_down_sync)
- 语义:
__shfl_up_sync(mask, var, delta):当前 lane 从lane_id - delta处读取__shfl_down_sync(mask, var, delta):当前 lane 从lane_id + delta处读取
异或模式(__shfl_xor_sync)
接口:
1
__shfl_xor_sync(mask, var, lane_mask, width = warpSize)
语义:当前 lane 从
lane_id ^ lane_mask对应的线程读取。典型用途:
- 实现蝶形(butterfly)通信模式
- 用于归约(reduction)、FFT 等需要对称交换的场景
示例:
- 当
lane_mask = 1- 对于
laneID = 0x00,0x01,0x10,0x11的 lane,需要与0x01异或,即从laneID = 0x01,0x00,0x11,0x10的 lane 获取数据,即相邻的 lane 交换数据
- 对于
- 当
lane_mask = 3- 对于
laneID = 0x00,0x01,0x10,0x11的 lane,需要与0x11异或,即从laneID = 0x11,0x10,0x01,0x00的 lane 获取数据,即lane0与lane3交换数据,lane1与lane2交换数据
- 对于
- 当
与共享内存方案的对比
优点:
更低延迟:数据直接在寄存器之间交换,不经共享内存
更高带宽:避免共享内存带宽、bank conflict 等瓶颈
无需显式同步:warp 内天然锁步执行,只要 mask 设置正确就不需要 __syncthreads()
节省共享内存:将共享内存资源留给真正需要跨 warp 或跨 block 的数据
缺点与限制:
仅限同一 warp:无法进行 block 级甚至 grid 级的数据交换
warp 尺寸固定:算法需要以 warp 为基本单位来设计
控制流发散敏感:如果 warp 内存在分支发散,必须确保活跃线程的 mask 一致,否则行为未定义
- Title: cuda
- Author: Ikko
- Created at : 2025-12-24 14:46:57
- Updated at : 2026-03-26 17:17:59
- Link: http://ikko-debug.github.io/2025/12/24/cuda/
- License: This work is licensed under CC BY-NC-SA 4.0.