
HYMBA论文粗总结

Hymba:小型语言模型的新标杆——融合SSM与Attention的混合架构
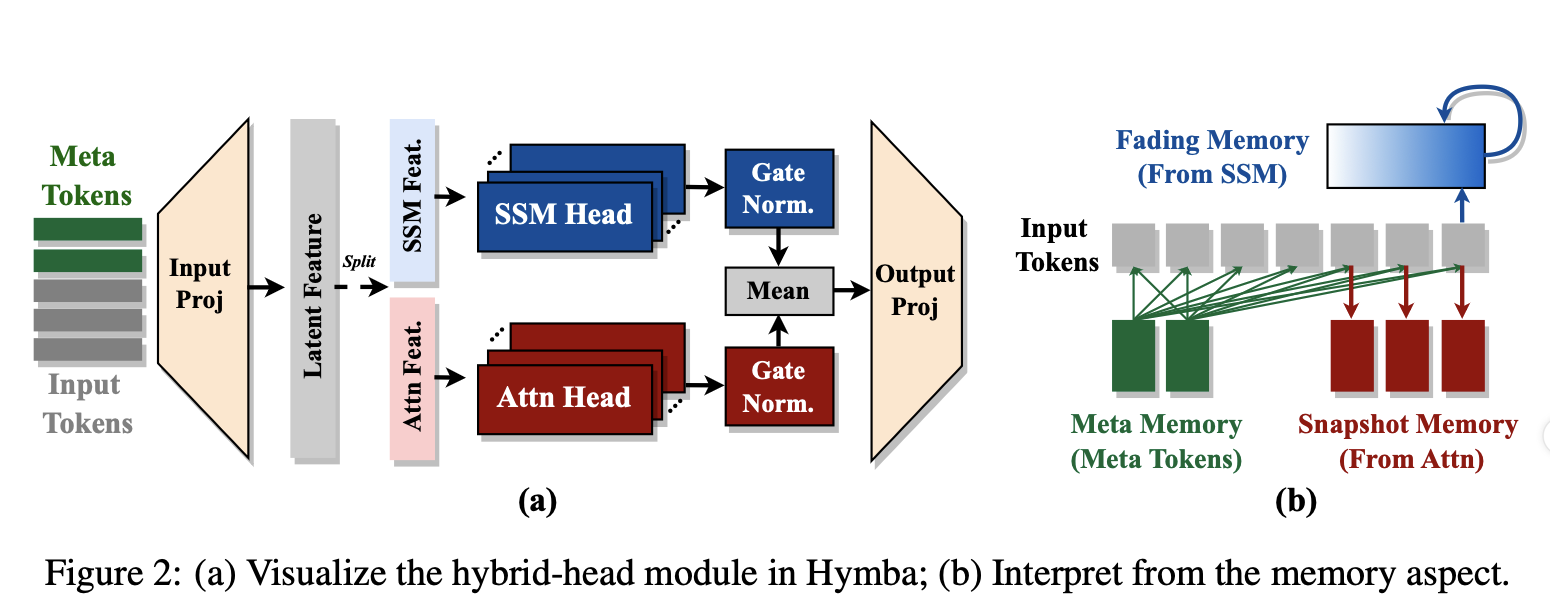
状态空间模型(SSM,如Mamba)以线性复杂度崭露头角,但其回忆能力不足。2025年ICLR,NVIDIA团队提出了Hymba,一种小型语言模型(LM),通过创新的“混合头”(Hybrid-Head)架构,巧妙融合SSM和Attention。
一、SSM(状态空间模型)的结构
SSM是一种基于控制论的序列建模方法,Mamba(Gu & Dao, 2023)是其代表。它通过线性复杂度处理长序列,成为Transformer的有力竞争者。
1.1 SSM的基本原理
SSM将序列建模视为一个动态系统,用状态转移方程描述输入到输出的映射:
- 输入:序列
,每个 。 - 状态:隐状态
(s是状态维度,如Hymba中的16)。 - 输出:
。
其离散形式为:
:状态转移矩阵。 :输入投影矩阵。 :输出投影矩阵。
1.2 Mamba的改进
Mamba在传统SSM基础上引入了数据依赖的参数和门控机制:
- 动态参数:
:固定但可学习。 :随输入动态变化。 :同上。 :时间步长,控制遗忘速度。
- 门控:引入门控向量
,输出为: - 计算:
- 递归形式:
。 - 并行形式(推理优化):用卷积或矩阵运算展开:
其中是预计算的转移函数。
- 递归形式:
1.3 SSM的优劣
- 优点:线性复杂度(
),小缓存(Hymba中仅1.87MB)。 - 缺点:低分辨率回忆,推理能力弱(Tab. 1显示Mamba在回忆任务仅19.23%)。
二、Hymba的结构
Hymba-1.5B是Hymba家族的主力型号,参数量1.52亿,专为小型设备设计。其架构以32层混合头模块为核心,融合了SSM和Attention,并引入优化策略。
2.1 总体架构
- 层数:32层。
- 隐藏维度:1600。
- 输入:原始序列
前置128个Meta Tokens,形成 。 - 输出:通过线性投影生成词汇概率。
参数配置
| 属性 | Hymba-1.5B |
|---|---|
| 层数 | 32 |
| 隐藏维度 | 1600 |
| SSM状态维度 | 16 |
| Attention头数 | 25 |
| 查询分组(GQA) | 5 |
| 全局注意力层 | 3(1、16、32) |
| 窗口大小 | 1024 |
| MLP隐藏维度 | 5504 |
2.2 混合头模块(Hybrid-Head Module)
每层是一个混合头模块,同时包含Attention和SSM头,输入
Attention头
- 数量:25个头。
- 计算:
。 - 头维度
。
- 类型:
- 全局(3层):完整序列。
- 局部(SWA,29层):窗口1024。
- GQA:25头分5组,共享键值。
SSM头
- 实现:基于Mamba。
- 计算:
:门控。 :输入特征。 同Mamba。
- 状态维度:16。
融合
- 输出融合:
:可学习缩放。 :平衡幅度差异(Fig. 9)。
2.3 Meta Tokens
- 数量:128个
。 - 作用:优化注意力分布,存储知识。
- 实现:训练时优化,推理时预计算为KV初始化。
2.4 KV优化
- 全局+局部:3层全局,29层SWA。
- 跨层共享:32层分13组,每组共享KV。
三、Hymba如何融合SSM与Attention
Hymba的融合方式是其最大亮点,区别于Jamba的串联设计,它采用并行融合:
3.1 并行处理
- 同一层内:输入
同时送入Attention和SSM头。 - 协同作用:
- Attention:提供“快照记忆”,高分辨率回忆(Tab. 1 recall从19.23%提升至51.79%)。
- SSM:提供“渐退记忆”,高效总结上下文。
- 对比串联:Jamba分层交替可能导致瓶颈,Hymba并行避免信息丢失(ERF更大,Fig. 8)。
3.2 输出融合
- 加权平均:Attention和SSM输出通过归一化和缩放融合,确保稳定性。
- 实验验证:Tab. 11显示并行优于拼接(concat),性能更高且参数更少。
3.3 Meta Tokens的桥梁作用
- 注意力引导:减少BOS关注(Fig. 11),让Attention更专注关键token。
- SSM增强:降低熵(Fig. 13),提升SSM的上下文提取能力。
3.4 KV优化的协同
- SSM支持:全局上下文由SSM总结,允许Attention用局部SWA。
- 结果:缓存减少11.67倍,吞吐量提升3.49倍(Tab. 2)。
四、前向传播伪代码
由原文伪代码理解得到
理解如下
输入:X = [x_1, …, x_n]
- 前置Meta Tokens:\tilde{X}^0 = [R, X]
- 遍历32层:
for i in [1, …, 32]:
if i in [1, 16, 32]: # 全局注意力
\tilde{X}^i = HymbaBlock-GA(\tilde{X}^{i-1})
else: # 局部注意力
if i是KV共享组首层:
\tilde{X}^i, KV^i = HymbaBlock-SWA(\tilde{X}^{i-1})
else:
复用上一层KV^{i-1}
\tilde{X}^i = HymbaBlock-SWA(\tilde{X}^{i-1}, KV^{i-1}) - 输出:最后一层结果经投影生成预测。
不过他给出的伪代码中并没有给出ssm的计算,于是在官方库推理代码中找到关键代码如下
解码器
1 |
|
attention计算
1 | if self.reuse_kv: |
ssm计算
1 | index = 0 |
融合
1 | hidden_states = (self.pre_avg_layernorm1(attn_outputs) + self.pre_avg_layernorm2(scan_outputs)) / 2 |
- Title: HYMBA论文粗总结
- Author: Ikko
- Created at : 2025-03-11 14:51:10
- Updated at : 2025-03-14 16:33:19
- Link: http://ikko-debug.github.io/2025/03/11/HYMBA/
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments