
MHA

MHA 和 GQA 中 Q、K、V 分割的区别解析
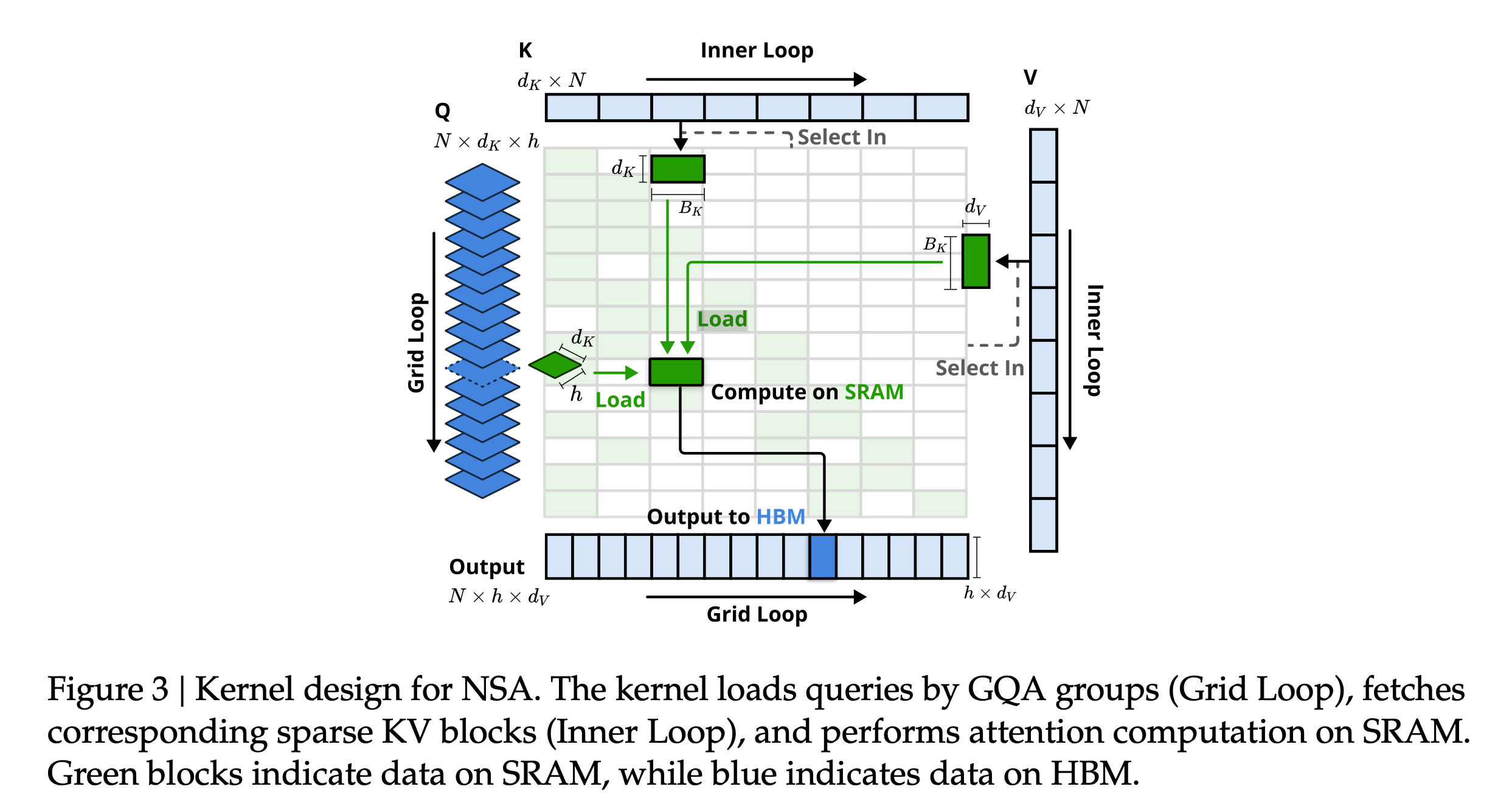
1. 图3的详细解析
1.1 整体布局
Figure 3 | Kernel design for NSA
The kernel loads queries by GQA groups (Grid Loop), fetches corresponding sparse KV blocks (Inner Loop), and performs attention computation on SRAM. Green blocks indicate data on SRAM, while blue indicates data on HBM.
展示 NSA 如何利用 GQA(Grouped-Query Attention)、稀疏选择和 GPU 内存层次(SRAM 和 HBM)优化计算效率。
1.2 关键元素
左侧:Grid Loop(网格循环)
左侧是一个蓝色柱状结构,标注为
( ),表示查询矩阵。 :序列长度。 :键的维度。 :注意力头的数量。
蓝色表示数据存储在 HBM(高带宽内存),用波浪线表示大数据量。
有一个向下箭头,标有“Grid Loop”,指向中间的“Inner Loop”区域,表示按 GQA 组加载查询。
“Grid Loop”是由 GPU 的网格调度器(grid scheduler)驱动的外循环,按 GQA 组(分组查询注意力)加载查询数据。
GQA 将
个头分成 组(论文中为 4 组,每组 16 个头),每组共享键值对,从而减少冗余加载。 数据从 HBM 加载到 SRAM(绿色区域)进行计算,优化内存带宽。
中间:Inner Loop(内循环)
中间区域标有“Inner Loop”,包含:
- 顶部有三条横向条带:
( )、 ( )、 ( ),表示查询、键和值矩阵。 - 从
和 中,通过虚线“Select In”选择稀疏键值块(绿色块,标注为 和 ),维度分别为 和 。 - 有一个“Load”箭头,从 HBM(蓝色)加载稀疏 KV 块到 SRAM(绿色),标有
和 。 - 绿色块标有“Compute on SRAM”,表示在 SRAM 上执行注意力计算。
- 底部有一个箭头“Output to HBM”,将结果写回 HBM。
- 顶部有三条横向条带:
“Inner Loop”是内循环部分,处理稀疏键值块的加载和计算。
“Select In”对应 NSA 的选择分支(Token Selection),通过 Top-n Block Selection 动态选择重要稀疏块(论文中
)。 键
和值 存储在 HBM,但只加载选中的稀疏块到 SRAM,减少内存访问。 在 SRAM 上利用 GPU 的 Tensor Core 计算注意力(
),降低延迟。 结果写回 HBM,作为最终输出。
右侧:稀疏 KV 块的加载
右侧是一个蓝色柱状结构,标注为
( ),类似左侧的 ,表示值的矩阵,存储在 HBM。 通过“Select In”选择稀疏块(绿色
),然后通过内循环加载到 SRAM。 有一个双向箭头“Inner Loop”,表示多次迭代加载不同稀疏块。
强调 NSA 的稀疏策略:只加载与当前查询相关的关键 KV 块(选择分支),大幅减少内存需求。
底部:Output(输出)
底部有一个横向条带,标注为“Output”(
),表示注意力输出。 输出条带部分蓝色(HBM),部分绿色(SRAM),并有一个箭头从“Compute on SRAM”指向“Output to HBM”。
这是计算结果的输出阶段,将 SRAM 中的中间结果写回 HBM。
输出维度符合 Transformer 的格式,供后续层使用。
1.3 颜色与内存层次
- 绿色:表示 SRAM(片上内存),速度快但容量有限,用于临时存储和计算。
- 蓝色:表示 HBM(高带宽内存),容量大但访问延迟高,用于存储完整数据。
- 设计目标:通过将计算推到 SRAM,减少 HBM 访问次数,优化内存带宽和算术强度。
2. 图3的动态流程
Grid Loop(外循环):
- 按 GQA 组从 HBM 加载查询
到 SRAM。 - 外循环通过网格调度并行处理不同查询块。
- 按 GQA 组从 HBM 加载查询
Select In(选择输入):
- 根据查询
,通过 NSA 选择分支确定稀疏 KV 块的索引 。 - 从 HBM 的
和 中选择对应稀疏块。
- 根据查询
Inner Loop(内循环):
- 逐个加载选中的稀疏 KV 块到 SRAM。
- 在 SRAM 上计算注意力(
),迭代次数由 决定。
Compute on SRAM:
- 利用 Tensor Core 在 SRAM 上高效计算,减少 HBM 访问。
Output to HBM:
- 将结果写回 HBM,作为最终输出。
3. 关于“MHA 和 GQA 中 Q、K、V 分割的区别”
3.1 MHA(Multi-Head Attention)的 Q、K、V 分割
过程:
在 MHA 中,输入序列
( 是序列长度, 是隐藏维度)通过线性变换生成 Q、K、V:
其中是可训练权重矩阵,维度分别为 、 、 。 分割:
- 将
沿着隐藏维度 分割成 个头(heads),每个头的维度为 (键和查询)或 (值):
其中或 。 - 每个头独立计算注意力:
- 最后将所有头的输出拼接并线性变换:
$$
\text{MultiHead}(Q, K, V) = \text{Concat}(\text{Head}_1, …, \text{Head}h) W_O
$$
其中 $W_O \in \mathbb{R}^{(h \cdot d_v) \times d{\text{model}}}$.
- 将
MHA 中 Q、K、V 都需要分割成多个头,每个头独立处理。这是 MHA 捕捉不同语义关系的核心特性。
3.2 GQA(Grouped-Query Attention)的 Q、K、V 分割
过程:
GQA 是 MHA 的优化版本,减少内存和计算开销。它同样从输入
生成 Q、K、V: 分组:
- 将
个查询头分成 组(groups),每组有 个头。 - Q 的分割:查询
被分割成 组,每个组的 对应每组的查询头。 - K 和 V 的共享:与 MHA 不同,GQA 中
和 不按头分割,而是每组共享一组 和 : 和 ,所有组使用相同的 和 。
- 将
注意力计算:
- 对每个组
计算注意力: - 最后拼接所有组的输出:
- 对每个组
GQA 中主要分割 Q(按组分),而 K 和 V 不按头分割,而是按组共享。这正是 GQA 减少内存需求(尤其是 KV 缓存)和提升效率的关键。
3.3 MQA(Multi-Query Attention)的 Q、K、V 分割
过程:
- MQA 可以看作 GQA 的极限情况(
)。输入同样先映射为: - 分割方式:
仍然分成 个头: - 但所有头共享同一组
和 (只有 1 组 KV)。
- MQA 可以看作 GQA 的极限情况(
注意力计算:
- 每个查询头都与同一组
做注意力: - 再将各头输出拼接并线性映射。
MQA 的核心是“多查询头 + 单组 KV”,KV 缓存最省,推理阶段吞吐通常更高,但表达能力一般弱于完整 MHA。
- 每个查询头都与同一组
3.4 对比总结
| 特性 | MHA | GQA | MQA |
|---|---|---|---|
| Q 的处理 | 分成 |
分成 |
分成 |
| K、V 的处理 | 分成 |
每组共享一组 |
全部头共享同一组 |
| KV 缓存开销 | 最高(约与 |
中等(约与 |
最低(与头数基本无关) |
| 计算效率 | 标准,训练友好 | 推理效率与效果折中 | 推理最快之一,长上下文更省带宽 |
| 效果上限 | 通常最高 | 接近 MHA(取决于 |
可能低于前两者(任务相关) |
- 关系总结:GQA 是从 MHA 向 MQA 的连续折中;当
时接近 MHA,当 时就是 MQA。
3.5 在 NSA 论文中的应用
- 图3 和 NSA 利用 GQA 的特性,通过“Grid Loop”按组加载查询(Q),并通过“Select In”选择稀疏 KV 块(共享的 K、V)。这与 GQA 的设计一致,减少冗余加载,提升硬件效率。
4. 通俗解释
- **MHA **:想象你在开会,64个人(64个头)每个人都记自己的笔记(Q、K、V 分成 64 份),讨论后汇总结果。效率不高,但能捕捉多种视角。
- **GQA **:把 64 人分成 4 组(4 个组),每组 16 人共用一本笔记(K、V 共享),但每个人有自己的问题(Q 分组)。讨论效率更高,适合快速决策。
- **MQA **:64 个人都提各自问题(Q 仍是多头),但全场只用一套公共资料(只有 1 组 K、V)。资料准备最快,最省内存。
- 分割区别:MHA 是每头独立 KV,GQA 是每组共享 KV,MQA 是所有头共享同一组 KV。
- Title: MHA
- Author: Ikko
- Created at : 2025-02-20 16:19:18
- Updated at : 2026-03-31 14:04:40
- Link: http://ikko-debug.github.io/2025/02/20/MHA/
- License: This work is licensed under CC BY-NC-SA 4.0.